In the previous post, we introduced the notion of leverage in linear regression. If we have a response vector 
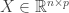







It turns out that leverage must satisfy the following bounds:
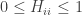
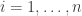
This is easy to prove using the following 2 facts:
- Note that
, i.e.
- Note that
, i.e.
Since 

- Since the RHS is a sum of square numbers,
.
- Since the second term on the RHS is a sum of square numbers,
, and since
.
There is also a constraint on the sum of leverages which is easy to derive. By the cyclic property of the trace operator,
![\begin{aligned} \sum_{i=1}^n H_{ii} &= \text{tr}(H) = \text{tr} [X(X^TX)^{-1}X^T] \\ &= \text{tr}[X^T X (X^T X)^{-1}] \\ &= \text{tr}(I_p) = p. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Csum_%7Bi%3D1%7D%5En+H_%7Bii%7D+%26%3D+%5Ctext%7Btr%7D%28H%29+%3D+%5Ctext%7Btr%7D+%5BX%28X%5ETX%29%5E%7B-1%7DX%5ET%5D+%5C%5C++%26%3D+%5Ctext%7Btr%7D%5BX%5ET+X+%28X%5ET+X%29%5E%7B-1%7D%5D+%5C%5C+%26%3D+%5Ctext%7Btr%7D%28I_p%29+%3D+p.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
