A linear Gaussian model is a model where (i) the input variables are jointly Gaussian, and (ii) the output variables are also jointly Gaussian, having means which are linear combinations of the input variables (and possibly a bias term). Linear Gaussian models are popular because in this model, several key quantities end up having Gaussian distribution with parameters which we can compute. Here is the main theorem:
Theorem. Assume that
Then
where

![\begin{aligned} p(y) &= \mathcal{N}\left( y \mid A\mu + b, L^{-1} + A \Lambda^{-1}A^\top \right) , \\ p(x \mid y) &= \mathcal{N} \left( x \mid \Sigma \left[ A^\top L (y - b) + \Lambda \mu \right], \Sigma \right), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+p%28y%29+%26%3D+%5Cmathcal%7BN%7D%5Cleft%28+y+%5Cmid+A%5Cmu+%2B+b%2C+L%5E%7B-1%7D+%2B+A+%5CLambda%5E%7B-1%7DA%5E%5Ctop+%5Cright%29+%2C+%5C%5C++p%28x+%5Cmid+y%29+%26%3D+%5Cmathcal%7BN%7D+%5Cleft%28+x+%5Cmid+%5CSigma+%5Cleft%5B+A%5E%5Ctop+L+%28y+-+b%29+%2B+%5CLambda+%5Cmu+%5Cright%5D%2C+%5CSigma+%5Cright%29%2C%C2%A0%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)

The details of the proof are a bit involved but the overall idea is quite simple. If you compute the log of the joint distribution 


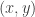
The result for the conditional distribution 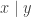
See Section 2.3.3 of Bishop (2006) (Reference 1) for the gory details.
References:
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning (Section 2.3.3).

Pingback: Using the Laplace method to approximate the posterior distribution of neural network parameters and outputs | Statistical Odds & Ends