A variable 
In this post, I introduce 3 commonly used methods for fitting regression models with an ordinal response. In what follows, I assume that the response variable 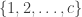

Cumulative logit model with proportional odds
The cumulative logit model with proportional odds assumes the following relationship between 
![\begin{aligned} \text{logit}[P(y \leq j)] = \log \dfrac{P(y \leq j)}{P(y > j)} = \alpha_j + \beta^T x, \qquad j = 1, \dots, c-1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Ctext%7Blogit%7D%5BP%28y+%5Cleq+j%29%5D+%3D+%5Clog+%5Cdfrac%7BP%28y+%5Cleq+j%29%7D%7BP%28y+%3E+j%29%7D+%3D+%5Calpha_j+%2B+%5Cbeta%5ET+x%2C+%5Cqquad+j+%3D+1%2C+%5Cdots%2C+c-1.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
This is a natural extension of logistic regression: there, we have 

Note that in this model, each value of 

![\begin{aligned} \log \left[ \dfrac{P(y \leq j \mid x_1) / P(y > j \mid x_1)}{P(y \leq j \mid x_2) / P(y > j \mid x_2)} \right] = \beta^T (x_1 - x_2). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Clog+%5Cleft%5B+%5Cdfrac%7BP%28y+%5Cleq+j+%5Cmid+x_1%29+%2F+P%28y+%3E+j+%5Cmid+x_1%29%7D%7BP%28y+%5Cleq+j+%5Cmid+x_2%29+%2F+P%28y+%3E+j+%5Cmid+x_2%29%7D+%5Cright%5D+%3D+%5Cbeta%5ET+%28x_1+-+x_2%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
With this model, the estimated probability of being less than or equal to
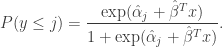
Hence, the estimated probability of being equal to

Adjacent-category logit model
The adjacent-category logit model assumes the relationship

Here the odds ratio uses only adjacent categories, whereas in the cumulative logit model it uses the entire response scale. Hence, the interpretation of the model is in terms of local odds ratios as opposed to cumulative odds ratios.
Having fit the model, the estimated probability of being equal to

This is quite a different form from that for the cumulative logit model.
Continuation-ratio logit model
The continuation-ratio logit model assumes the relationship
![\begin{aligned} \text{logit} [P(y = j \mid y \geq j)] = \log \dfrac{P(y = j \mid y \geq j)}{P(y > j \mid y \geq j)} = \alpha_j + \beta^T x, \qquad j = 1, \dots, c-1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Ctext%7Blogit%7D+%5BP%28y+%3D+j+%5Cmid+y+%5Cgeq+j%29%5D+%3D+%5Clog+%5Cdfrac%7BP%28y+%3D+j+%5Cmid+y+%5Cgeq+j%29%7D%7BP%28y+%3E+j+%5Cmid+y+%5Cgeq+j%29%7D+%3D+%5Calpha_j+%2B+%5Cbeta%5ET+x%2C+%5Cqquad+j+%3D+1%2C+%5Cdots%2C+c-1.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Having fit the model, we have the estimated conditional probabilities

With a bit of algebra we can convert them to unconditional probability estimates:
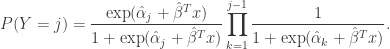
References:
- Agresti, A. (2010). Modeling Ordinal Categorical Data.
