Assume that we are in the regression context with response  and design matrix
and design matrix 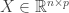 . The LASSO solves the following minimization problem:
. The LASSO solves the following minimization problem:
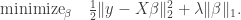
The LASSO is a special case of bridge estimators, first studied by Frank and Friedman (1993), which is the solution to
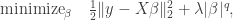
with 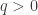 . The LASSO corresponds to the case where
. The LASSO corresponds to the case where 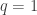 and ridge regression corresponds to the case where
and ridge regression corresponds to the case where 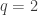 . We typically do not consider the case where
. We typically do not consider the case where 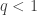 as it results in a non-convex minimization problem which is hard to solve for globally.
as it results in a non-convex minimization problem which is hard to solve for globally.
When the design matrix is orthogonal, the minimization problem above decouples, and we obtain the LASSO estimates 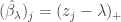 , where
, where 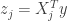 is the OLS solution. This is known as soft-thresholding, where we reduce something by a fixed value (in this case
is the OLS solution. This is known as soft-thresholding, where we reduce something by a fixed value (in this case  ) without letting it go negative.
) without letting it go negative.
It’s nice to have a thresholding rule in the orthogonal case; it’s also nice for the solution to be continuous in 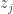 . Fan & Li (2001) show that the only bridge estimator which has both these properties is the LASSO.
. Fan & Li (2001) show that the only bridge estimator which has both these properties is the LASSO.
One problem with the LASSO is that the penalty term is linear in the size of the regression coefficient, hence it tends to give substantially biased estimates for large regression coefficients. To that end, Fan & Li (2001) propose the SCAD (smoothly clipped absolute deviation) penalty:
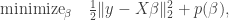
where the derivative of the penalty function is
![p'(\beta) = \lambda \left[ I(\beta \leq \lambda) + \dfrac{(a\lambda - \beta)_+}{(a-1)\lambda}I(\beta > \lambda) \right],](https://s0.wp.com/latex.php?latex=p%27%28%5Cbeta%29+%3D+%5Clambda+%5Cleft%5B+I%28%5Cbeta+%5Cleq+%5Clambda%29+%2B+%5Cdfrac%7B%28a%5Clambda+-+%5Cbeta%29_%2B%7D%7B%28a-1%29%5Clambda%7DI%28%5Cbeta+%3E+%5Clambda%29+%5Cright%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
with 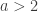 . This corresponds to a quadratic spline function with knots at and
. This corresponds to a quadratic spline function with knots at and  . Explicitly, the penalty is
. Explicitly, the penalty is
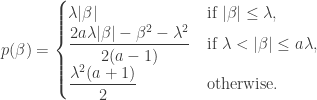
Below is a plot of the penalty function, where we have set 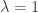 and
and 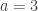 . The SCAD penalty function is in red while the LASSO penalty function is in black for comparison. The dotted lines are the penalty’s transition points (
. The SCAD penalty function is in red while the LASSO penalty function is in black for comparison. The dotted lines are the penalty’s transition points (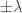 and
and 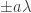 ).
).

Under orthogonal design, we get the SCAD solution
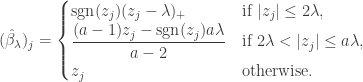
The plot below shows what the SCAD estimates look like (, ). The dotted line is the 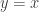 line. The line in black represents soft-thresholding (LASSO estimates) while the line in red represents the SCAD estimates. We see that the SCAD estimates are the same as soft-thresholding for
line. The line in black represents soft-thresholding (LASSO estimates) while the line in red represents the SCAD estimates. We see that the SCAD estimates are the same as soft-thresholding for 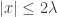 and are equal to hard-thresholding for
and are equal to hard-thresholding for 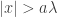 ; the estimates in the remaining regions are linear interpolations of these two regimes.
; the estimates in the remaining regions are linear interpolations of these two regimes.

References:
- Fan, J., and Liu, R. (2001). Variable selection via penalized likelihood.
- Breheny, P. Adaptive lasso, MCP, and SCAD.

Pingback: The minimax concave penalty (MCP) | Statistical Odds & Ends