Elastic weight consolidation (EWC) is a technique proposed by Kirkpatrick et al. (2016) (Reference 1) as a way for avoiding catastrophic forgetting in neural networks.
Set-up and notation
Imagine that we want to train a neural network to be able to perform well on several different tasks. In real-world settings, it’s not always possible to have all the data from all tasks available at the beginning of model training, so we want our model to be able to learn continually: “that is, [have] the ability to learn consecutive tasks without forgetting how to perform previously trained tasks.”
This turns out to be difficult for neural networks because of a phenomenon known as catastrophic forgetting. Assume that I have already trained a model to be good at one task, task A. Now, when I further train this model to be good at a second task, task B, performance on task A tends to degrade, with the performance drop often happening abruptly (hence “catastrophic”). This happens because “the weights in the network that are important for task A are changed to meet the objectives of task B”.
Let’s rewrite the previous paragraph with some mathematical notation. Assume that we have training data 



Let’s say that training on task A gives us the network parameters 

Elastic weight consolidation (EWC)
The intuition behind elastic weight consolidation (EWC) is the following: since large neural networks tend to be over-parameterized, it is likely that for any one task, there are many values of  How do we make this intuition concrete? Assume that we are in a Bayesian setting. What we would like to do is maximize the (log) posterior probability of
How do we make this intuition concrete? Assume that we are in a Bayesian setting. What we would like to do is maximize the (log) posterior probability of 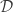

Note that the equation above applies if we replace all instances of
![\begin{aligned} \log p(\theta | \mathcal{D}) &= \log p(\mathcal{D}_A | \theta) + \log p(\mathcal{D}_B | \theta) + \log p(\theta) - \log p(\mathcal{D}_A) - \log p(\mathcal{D}_B) \\ &= \log p(\mathcal{D}_B | \theta) + \log p(\theta) - \log p(\mathcal{D}_A) - \log p(\mathcal{D}_B) \\ &\qquad + [\log p(\theta | \mathcal{D}_A) - \log p(\theta) + \log p (\mathcal{D}_A) ] \\ &= \log p(\mathcal{D}_B | \theta) + \log p(\theta | \mathcal{D}_A) - \log p(\mathcal{D}_B). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Clog+p%28%5Ctheta+%7C+%5Cmathcal%7BD%7D%29+%26%3D+%5Clog+p%28%5Cmathcal%7BD%7D_A+%7C+%5Ctheta%29+%2B+%5Clog+p%28%5Cmathcal%7BD%7D_B+%7C+%5Ctheta%29+%2B+%5Clog+p%28%5Ctheta%29+-+%5Clog+p%28%5Cmathcal%7BD%7D_A%29+-+%5Clog+p%28%5Cmathcal%7BD%7D_B%29+%5C%5C++%26%3D+%5Clog+p%28%5Cmathcal%7BD%7D_B+%7C+%5Ctheta%29+%2B+%5Clog+p%28%5Ctheta%29+-+%5Clog+p%28%5Cmathcal%7BD%7D_A%29+-+%5Clog+p%28%5Cmathcal%7BD%7D_B%29+%5C%5C++%26%5Cqquad+%2B+%5B%5Clog+p%28%5Ctheta+%7C+%5Cmathcal%7BD%7D_A%29+-+%5Clog+p%28%5Ctheta%29+%2B+%5Clog+p+%28%5Cmathcal%7BD%7D_A%29+%5D+%5C%5C++%26%3D+%5Clog+p%28%5Cmathcal%7BD%7D_B+%7C+%5Ctheta%29+%2B+%5Clog+p%28%5Ctheta+%7C+%5Cmathcal%7BD%7D_A%29+-+%5Clog+p%28%5Cmathcal%7BD%7D_B%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Thus, maximizing the log posterior probability of

Assume that we have already trained our model in some way to get to 
Putting it altogether, maximizing 

where 

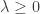

Why the name “elastic weight consolidation”? From the authors:
“This constraint is implemented as a quadratic penalty, and can therefore be imagined as a spring anchoring the parameters to the previous solution, hence the name elastic. Importantly, the stiffness of this spring should not be the same for all parameters; rather, it should be greater for those parameters that matter most to the performance during task A.”
References:
- Kirkpartick, J., et al. (2016). Overcoming catastrophic forgetting in neural networks.
