In R, I frequently find myself trying to extract elements out of a tibble. This is especially the case when I’m trying to take out a summary statistic.
For example, the code below produces the mean of the hwy column in the vehicles dataset:
library(dplyr) library(fueleconomy) data(vehicles) mean_hwy <- vehicles %>% summarize(mean_hwy = mean(hwy)) mean_hwy # # A tibble: 1 x 1 # mean_hwy # <dbl> # 1 23.6
Let’s say I want to extract 23.6 from the 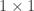
mean_hwy[1,1] # # A tibble: 1 x 1 # mean_hwy # <dbl> # 1 23.6
The way to get around this is to use $ or [[, as you would when subsetting a list:
mean_hwy[[1]] # [1] 23.55128 mean_hwy$mean_hwy # [1] 23.55128
For more details, see R for Data Science‘s chapter on Tibbles.
Update (2019-08-29): As Paul mentions in the comments, the dplyr package has a pull() function which allows you to extract a column as a vector:
mean_hwy %>% pull(mean_hwy) # [1] 23.55128

Hello Kenneth, you can use dplyr::pull for that:
mean_hwy % summarize(mean_hwy = mean(hwy)) %>% pull()
mean_hwy
# [1] 23.55128
LikeLike
I didn’t know the pull function existed before. Thanks for the tip!!
LikeLike
Thank you!! This was super helpful!
LikeLike
thanks
LikeLike